
All of the GitHub
I'm deep in the second year of my master's program now, and as time goes on I sink more and more into a reclusive lifestyle with only my running and my thesis project for company. In this post I'll validate my existence and share some information on what my project is about. I'm also going to dump here a big old dataset I have collected from GitHub for my work.
(quick note: GitHub is the most popular web site for people to host programming source code and other random activities)
Something about the project
In short, my project is to create a model that will detect inconsistent comments. Give my model a natural language comment and a piece of code, and it will tell you whether they belong to each other.
def make_a_list(n):
'''This function returns a SET of n numbers.'''
return list(range(n))
Bad comment!
Motivation: In my past life as a professional software engineer, one of the most frustrating obstacles to learning a new software system was outdated or misleading comments. By the second law of thermodynamics, this is of course bound to happen. The developers preceding me had fixed bugs or implemented functionality by changing code, but nothing forced them to update the comments as well. Even if engineers pay close attention 99% of the time, that last 1% will build up over the years until the point where new developers will simply ignore comments because they have lost faith in their accuracy.
The goal of this project is to catch that 1%.
Now if you're detail-oriented and familiar with software, this summary's definitely going to raise some questions about how this all works. For now, perhaps I can placate your curiosity by offering a poster I have made for my initial feasibility study. Future posts will go into more detail on what exactly I'm doing. There's a subscribe button somewhere if you want to be notified when that happens.
Okay, there is one question I can answer now.
Question: Can't ChatGPT do this already? 🧐🧐🧐
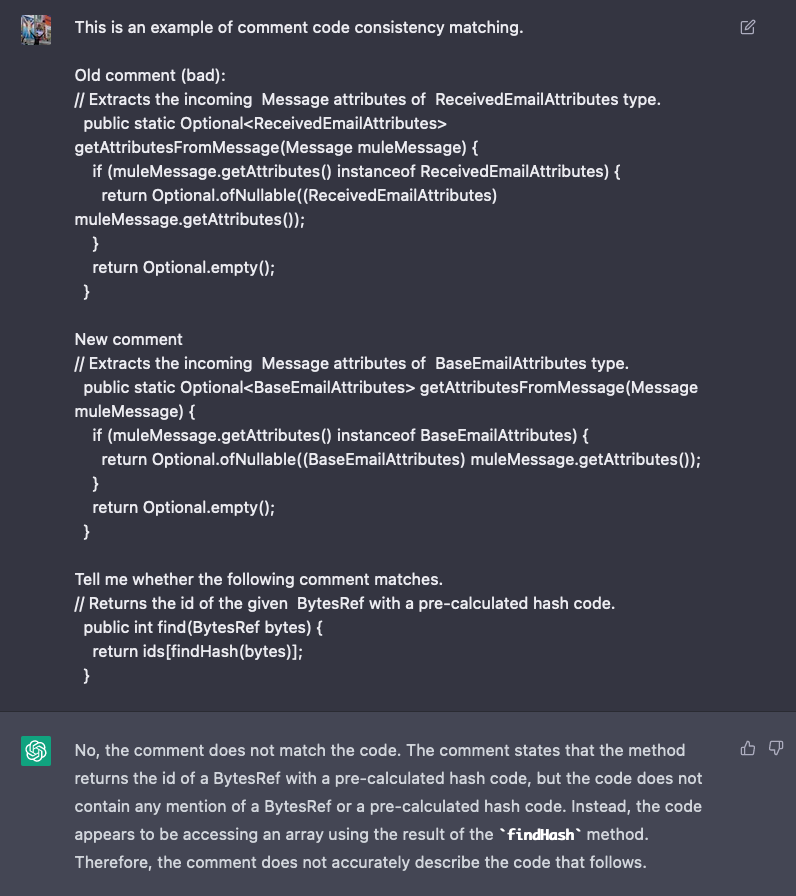
Answer: Yes, of course it can. It can do everything. I tried 2 samples from my training set, and after priming it with a prompt describing my definition and a few labeled examples, it got both correct. But even a blind turtle could get that performance 1 in 4 times. Whether it scales to many different examples is still an open question, and perhaps the more challenging issue is that it's difficult to tease out a degree of confidence for its responses because Mr. ChatGPT is always supremely confident. That might not be desirable if you want to tune the model's tradeoff between precision and recall, for example.
(side note: I saw a student working at a café with ChatGPT in one tab and their homework submission page in another. Good for them if it works, I suppose, but I can't help but dread what if everyone does that for everything? Personally I'm already reading anything I see online with half my mind trying to discriminate whether it was written by a bot. Really helps with anxiety issues. How about you, have you already lost your trust too? Should I pivot my model to detecting generated natural text?)
The Dataset
Before I can even dream about a model, I need to have a way to collect data to train it. Ideally, I want to have high-quality data that is diverse but matches very closely with the task description. That means I want to find examples of real people fixing inconsistent comments in code.
Back in the days when I worked at a Big Tech Company, obtaining high-quality data would have been much easier. I could trust that every code change was at least reviewed by another human, and the author and reviewer often left a trail of discussion as requests were made and new revisions were updated. If you (the hypothetical you that works at Big Tech) wanted to collect data samples, you could look for discussions that mention something similar to "fix comment" and pull out the relevant code.
Unfortunately this practice of reliable code review is definitely not the standard in the academic and open source worlds. It still exists but only in the corners and you'll only find it if you look very thoroughly. Which I did, but talking about that's for another post too.
The dataset I'm sharing here is called GitHub Public Repository Metadata. It's currently available from Kaggle. It contains almost three million entries of repository metadata, meaning information like how many stars a repository has, which programming languages it contains, when it was created, and the number of commits to it.
Example Entry:
{
"owner": "pelmers",
"name": "text-rewriter",
"stars": 11,
"forks": 4,
"watchers": 3,
"isFork": false,
"isArchived": false,
"languages": [ { "name": "JavaScript", "size": 21769 }, { "name": "HTML", "size": 2096 }, { "name": "CSS", "size": 2081 } ],
"diskUsageKb": 75,
"pullRequests": 4,
"description": "Webextension to rewrite phrases in pages",
"primaryLanguage": "JavaScript",
"createdAt": "2015-03-14T22:35:11Z",
"pushedAt": "2022-02-11T14:26:00Z",
"defaultBranchCommitCount": 54,
"license": null,
"assignableUserCount": 1,
"codeOfConduct": null,
"forkingAllowed": true,
"nameWithOwner": "pelmers/text-rewriter",
"parent": null
}
This 1.8 GB collection of metadata is really just the first step towards the data I will use to train my model. As I mentioned, we want to train with high quality code. While GitHub certainly has a lot of code, it also has a lot of not so high quality code. Therefore I'll use this metadata collection to filter out repositories that mitigate the perils of mining GitHub. That means coming up with criteria to exclude homework assignments, one-man side projects, template code, and the like.
Data Collection Details
If you are considering a similar work, you might be interested in how the data collection is done. Lucky for you, I'm sharing the collection script in the accompanying GitHub repository. The main complication in gathering the data comes from the pagination limit of the GitHub API.
Even if there are millions of results matching your query, their API only lets you see the first 1000 items. To get around this limmiation, this script performs bisection on the space of stars and creation dates to chunk the entire web site into regions of no more than 1000 items. For example, if on 1/1/23 there are 1500 repositories with 11-20 stars, we will split the query into two: one from 11-15 and one from 16-20 stars. In total this process produces around 4500 queries.
Fun fact: back in the day I used this two-dimensional bisection approach to find Strava segments with the slowest record pace.
Note that free access to the GitHub API is quite slow; data collection takes approximately 4 days to fully complete.
H-index for research, G-index for Github?
I know this post is quite dry, so let's end with something at least a little bit interactive.
In the research world, the h-index of an author is the maximum number h where she has h papers with at least h citations each. If her h-index is 10, then you know she has published 10 papers where each has at least 10 citations. It's an interesting metric, though taken to the extreme leads to behavior like citation cliques of researchers that boost each other's h-index rankings or publishing the same research with very different titles each time.
Anyway, we can extend this metric to GitHub. Let's define someone's g-index as the maximum number g where she has g repositories each with at least g stars. Indeed, this isn't my original idea; Dan Vanderkam created such a ranking back in 2020. Three years later (what???) let's take a look at the new top 10.
Top 10 authors by g-index (g repos with at least g stars):
microsoft: 411
google: 359
apache: 231
sindresorhus: 228
facebookresearch: 208
Azure: 173
spatie: 171
alibaba: 164
PacktPublishing: 159
googlearchive: 149
Looks like Microsoft is winning this time. And it's interesting that facebook is missing even though facebookresearch is in the top 5.
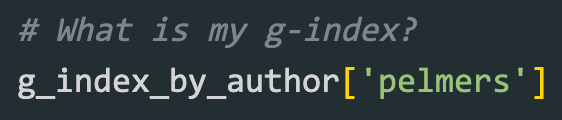
By the way, my own g-index is 5.
Do you want to know yours? I have prepared a notebook to answer this question. Just change the output to your username in the last cell of this file!
View Comments