
Finishing a Master's
A week ago I presented my master's thesis to my defense committee, marking the completion of the months-long project. So even though I'm not terribly eager to return to the topic, I feel compelled to write down a little summary of what I spent most of this year working on.
What the Comment?!
The title of my thesis, Large Language Models for Code Comment Consistency, is not exactly the pinnacle of imagination, but it does convey the nature of the problem (incidentally, I thought of going with What the Comment?!). Specifically, my project was to investigate whether we could use large language models to automatically classify comments as consistent or inconsistent with the code they refer to.
To illustrate, here's a simple example, written in Python.
def energy(mass, height):
"""
This function returns the kinetic energy of an object.
"""
return G * mass * height
Note that the function is computing the potential energy of an object, but the comment says it is going to return the kinetic energy! That's an inconsistent comment, exactly the sort of mistake we want to find.
By the way, before I explain further, if you happen to be very interested in the meat of this project, you can read the entire 50 page thesis paper here. The replication code is available on my GitHub, and the following datasets are available on Kaggle:
- 3 million+ public repository metadata
- 1 million+ labeled pairs of code and comment
- 13 million+ public pull request comments
Who cares???
In the paper, you'll find this section under Motivation. Recently, all the hype in the AI world has been in generative modeling, i.e. models that create new things like words, music, pictures, or art. I actually wrote a post about some of my thoughts on this previously, but in short, there are a few potential pitfalls to generating our way out of everything.
Specifically in software development, we know that 83% of the time a professional developer spends on his or her job is on code navigation and understanding. That means the bottleneck of programming work is reading, not writing! My personal experience bears that out, and this conclusion isn't a big revelation. Any line of code might be written by one person but will be used and scrutinized by many.
The takeaway of this point is that if we want to help developers be more productive, aiding their reading gives the greatest return. We already know this; that's why we write comments in the first place! Humans leave notes for other humans. What might go wrong is when the code is changed but the comment is not. In my example above, how will someone know whether the comment is correct or the code is correct? He or she will have to examine every usage of the function to decide.
If you're finding yourself in agreement with this premise, I want to point you to a solution I've already made and wrote about, my Code Couplet VS Code extension that lets you lock together comments and code so you'll be warned if you change one and not the other. The tagline: a typechecker for your comments!
You can think of this thesis project as an automated version of that extension. Oh, and why use LLMs? Well, I have to justify my master's in data science somehow...
Great, but how??
Look for Methodology in the paper if you really want all the details. In short, the approach I took is to mine lots of code data from GitHub, then, based on the change histories, create datasets of code and comment pairs labeled as consistent or inconsistent. The preparation for this large scale mining actually began in January, when I wrote All of the Github and published a dataset of 3 million repository metadata entries (note: the number has already grown by 5% since then). Finally, once we have all the data, we just need to train some language models and run the experiments.
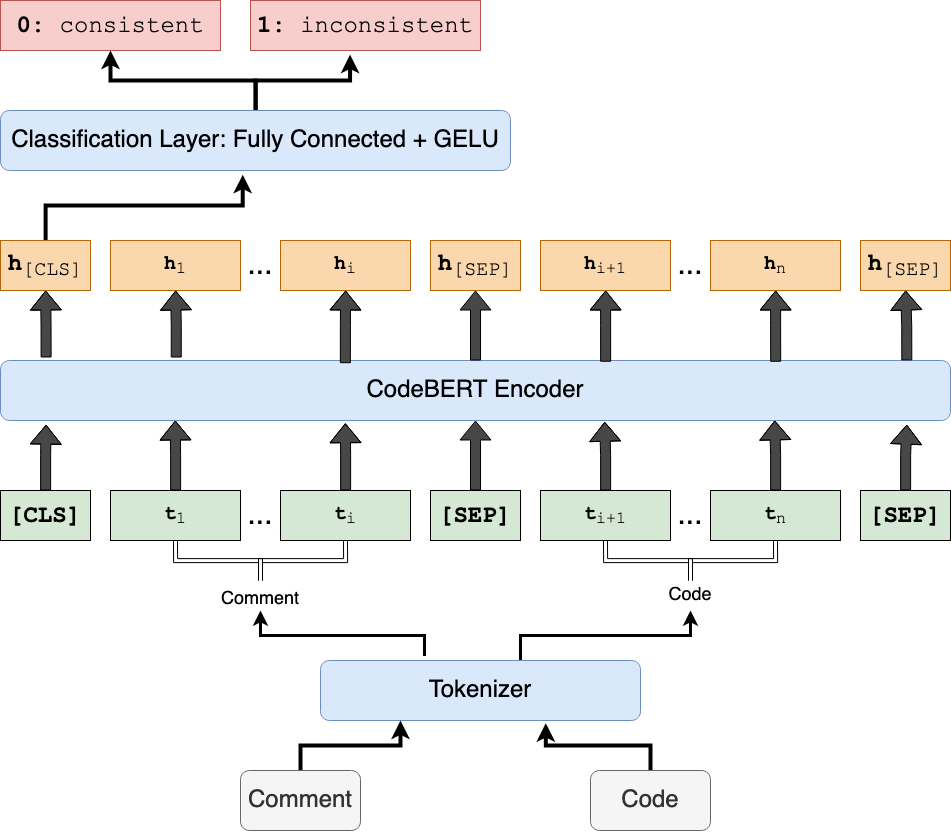
It's solved now?
Nope, the overall result is negative. That's also why I wasn't in a big rush to write this post following my defense. It turns out that under the problem formulation with the models I chose, the observed performance is better than random guessing.... but not by enough to make it any kind of usable tool.
Of course, I picked this project with the hope that results would be positive and we could make something that reliably predicts consistent or inconsistent comments. In fact, existing work already showed that was achievable, giving more than 80% accuracy on a Java dataset.
The problem: the dataset used in previous work has an artifact where 83% of the examples could be correctly predicted just based on the last two characters of the input. All inconsistent examples had two empty lines at the end, and most consistent examples had only one empty line at the end. Oops. 🙃

I remember back in April frantically trying to reconcile why the models performed so badly on my new datasets and yet excelled on the previous datasets. I did all kinds of tests on my training code and the data samples I had gathered, but I couldn't find anything wrong. I spent days mining and re-mining all the data, changing the project filtering criteria, and fiddling with training parameters. Unfortunately, it turned out the problem was in the last place I looked.
However, my project did not end with the modeling results. I also sent 20 public pull requests to fix comment consistency issues I identified. The idea of this study was to gauge the value of addressing comment mistakes in the real world. In the end, 90% (18 of 20) pull requests were accepted, so I'll take that as a positive. A few years ago that earned me a T-shirt, but now I'm getting nothing for my efforts!
Then what's next?
For now, I'm done with new research on this topic. We're working on condensing the thesis into a research paper and submitting to a relevant conference, and hopefully that will wrap the work up with a nice conclusion.
But that doesn't mean the problem is unsolveable! For anyone who wants to pick up where I left off, I refer them to the Future Work section of my thesis. In short, I believe the models need a little more context for a reliable judgment, meaning that the comment and its function alone is not enough to be accurate in most cases.
View Comments